Loading
Automated County Go-Live Migration Pipeline
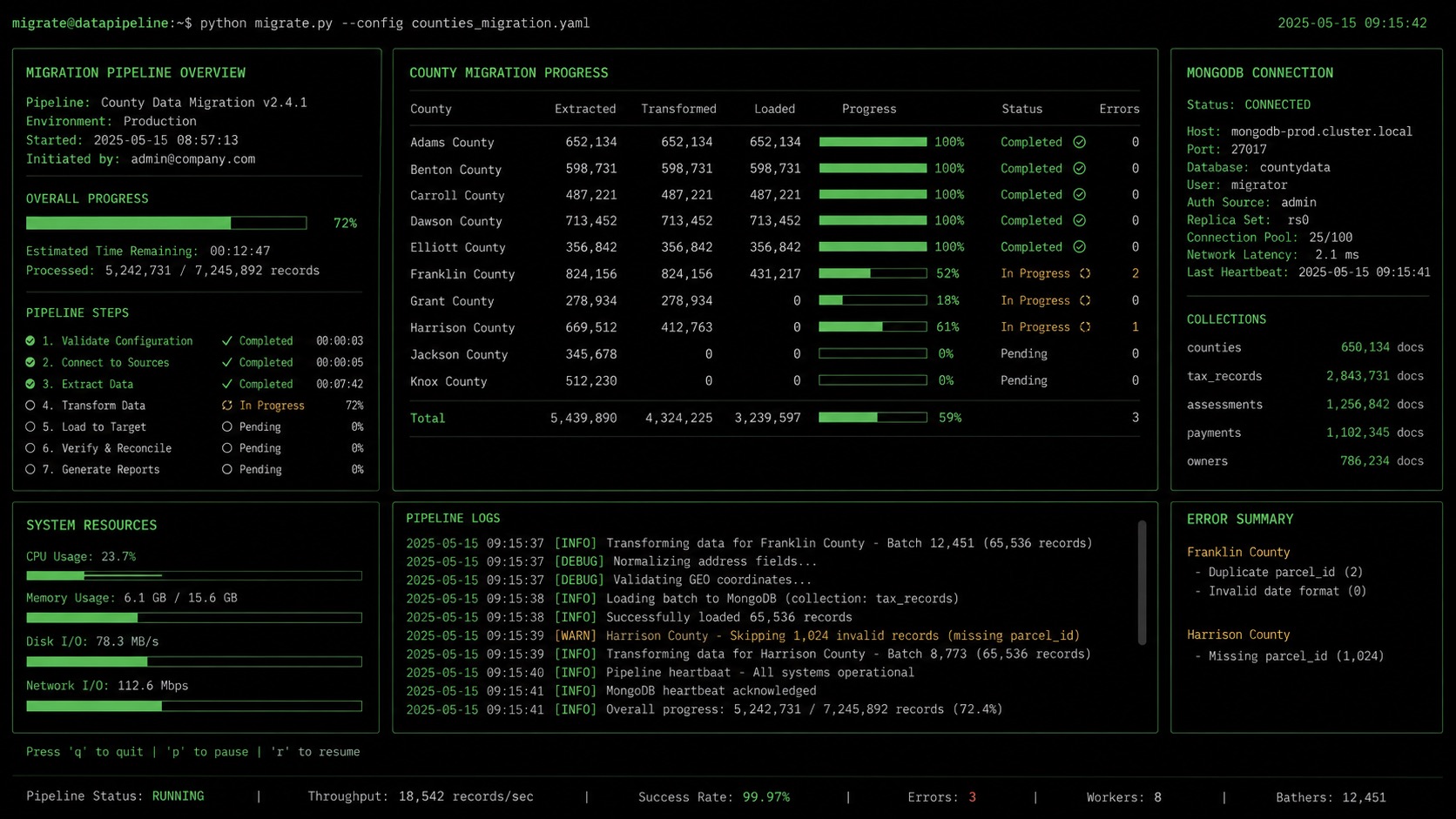
A fully automated pipeline for migrating county government offices from an aging on-premise legacy system to a cloud-hosted SaaS platform — handling data extraction, transformation, bulk import, and post-migration validation at scale.
Each county migration involves 650,000+ tax records and 120,000+ scanned documents. The pipeline automates a sequence that previously required days of manual work, reducing go-live execution time dramatically while maintaining data integrity through multi-stage verification.
Architecture
- • Browser Automation: Playwright (Node.js) — navigates legacy system UI, extracts records, handles authentication, submits import forms in the new platform
- • Data Layer: MongoDB Atlas — target database for all migrated records; port-forwarded via Kubernetes for local pipeline access during import
- • Verification: Post-import checksum validation, fund alt-key mapping verification, record count reconciliation, balance integrity checks
- • Document Migration: Scanned document transfer with filename normalization and association to tax records
- • Reporting: Automated go-live checklist generation — each step verified and logged before sign-off
What I Built
- • Full migration automation script (migration-import-v2.js) — county-by-county sequential processing, configurable batch sizes, retry logic
- • Legacy system data extraction — Playwright browser automation against the legacy Windows application UI for counties without a data export API
- • Post-migration verification suite — fund alt-key mapping checks (0001=GEN, 1102=MVF, etc.), balance reconciliation, record count diffs
- • Go-live checklist automation — generates completed verification reports for each county at cutover
- • Direct MongoDB writes via Node.js — for cases where the import API couldn't handle edge-case record formats from legacy data
Scale
18
Counties Migrated
650K+
Tax Records per County
120K+
Documents per County
0
Data Loss Incidents
Project Info
CLIENT
Government Tax Administration
MY ROLE
Software Engineer / Automation
DURATION
Feb 2025 – Present
STACK
Node.js · Playwright · MongoDB Atlas · Kubernetes · Python
DOMAIN